

Како да извучете текст са слике

- 4990
- 1190
- Mrs. Glenn Cruickshank
Пре сваког корисника рачунара барем након што је било потребно да се добију текстуалне информације са слика. Радећи у програмима за регрутовање, понекад морате преписивати текст у растеру или векторској слици. Овај дуг процес се може смањити ако знате како да повучете текст у реч са слике.
Да бисте текст претворили на слику у реч документ - следите упутства испод
Излаз
Обично је процес препознавања са сликом прилично напоран. То ће морати да ручно уради главни рад у њему, али коначни резултат ће уштедети укупно проведено време. Ово је неопходно када је на располагању само електронска слика документа или странице књиге, од којих је потребно да изађете у текст.
Уместо сопствених информација о поновном штампању, можете користити специјализоване програме и услуге које аутоматизују овај рад. Омогућују вам да препознате текст користећи слике најпопуларнијих формата, укључујући ЈПГ, ГИФ и ПНГ.
Редослед рада
Ако су подаци на штампаном документу, мораће да предигне слику од њега. Ово ће захтијевати скенер. Такође је неопходно ако текст на слици има лошу резолуцију или је замагљен. "Матични" управљачки програми и програми који ће превести све у високој квалитети треба да буду приложени скенеру. Резултат је погођен не само јасноћом писама, већ и по њиховом "чак" положају, као и недостатак сметњи.

Ако требате да добијете текст са папирног медија, потребан вам је скенер
Ако имате скенер, можете добити са камером. У овом случају морате правилно поставити светло. Следећа фаза захтева употребу посебних програма који ће вам омогућити да директно препознате текст са ЈПГ-ом. Међу таквим програмима, Аббии ФинеРеадер заузима посебно место које се сматра вођом на тржишту. Плаћа се, али његов квалитет одговара трошковима.
Карактеристике процеса
Много је функција у функционалности софтвера за рад са већином фонтова. Међу напредним могућностима постоји могућност препознавања рукописаног текста речи из ЈПГ-а. Има много предности:
- Избор квалитета. Сам корисник може зауставити жељени квалитет за скенирање. Боље је изабрати најмање 300 дпи тако да програм утиче и на мале делове за обраду и може да ради са малим фонтовима.
- Боја. Потребно је када на слици постоје столови или други симболи. У другим опцијама, пожељно је одабир црно-белог режима, који ће уклонити премештање боје у распону од слова, чинећи их чистијим. Режим боја је погодан за светле слике, где је важно пренијети боју текста.
- фотографија. Ако слика направи слику, програм ће повећати приоритет скенирања. Такође можете да сликате текст директно са Аббии ФинеРеадер да бисте је препознали у ЈПГ. Тачно, ово ће се увелико погоршати квалитет, због чега ће коначни резултат имати много грешака.
Међу сличним програмима постоје и бесплатне услуге. Међу њима је и означено и Гоогле погон, који је доступан директно у прегледачу. Рад са ОЦР Цонверт има просечан квалитет, па је погодан за оне чија слика има високу експанзију и бистре фонтове. Услуга И2Окра нуди сличне услуге, само слике се такође могу преузети са УРЛ везе. Они имају више аматерског формата, према томе, они се не сматрају професионалним употребом.
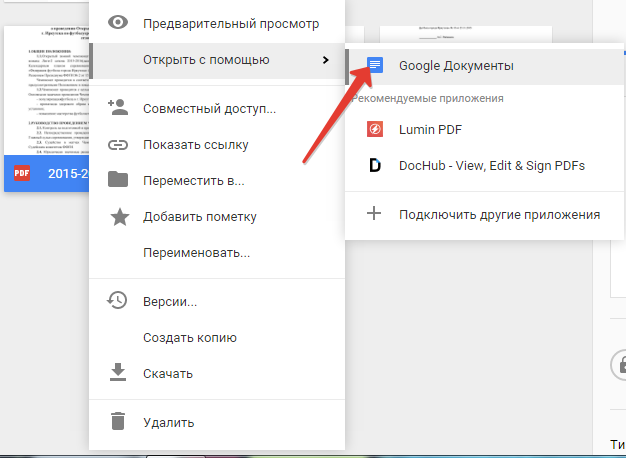
Након што је отварање слике путем Гоогле докумената, добит ћете документ са већ препознатим текстом
Резултат
Након почетка скенирања, обично је потребно неколико минута да се добије резултат. Овај индикатор зависи од сложености и количине тела. Након почетка рада програми у аутоматском режиму ће доделити подручја за верификацију и претворити их. Након завршетка поступка, можете поново препознати ЈПГ податке или се фокусирати на одређене области документа.
Готов резултат се извози у реч датотека. Добијени текст се може уређивати приликом посматрања грешака или наставите даље радити са њим. Препознати текст из ЈПГ слика није тешко ако је слика правилно припремљена. Овај процес може значајно уштедети време, за разлику од ручно репризивајући информације.
Пошто је рад са препознавањем текста са слике, потребан је висококвалитетни извор, морате да у почетку можете да пронађете слику високе резолуције. То ће се убрзати процес самог обраде података и такође ће смањити укупну количину грешака.